The Future of the Censorship Industrial Complex
I just got finished listening to Matt Taibbi’s podcast with Walter Kirn from July 7 that discusses the Missouri v. Biden Court ruling in which Biden appointees requested that social media companies censor so-called “disinformation” on a wide variety of topics. 1
Co-host Walter Kirn speculated that this “censorship industrial complex” will not end with a court loss, but once established, may seek to work around new constraints.
So what are independent journalists to do to counter this new concentration of power?
I’ve been working on an App called CiteIt that may help with this ..
Is talk of US involvement in the Nord Stream bombing officially flagged as “Disinformation”?

Is this Nord Stream bombing article Disinformation?
Episode 46 of America This Week got me wondering about whether possible US involvement in the Nord Stream bombing was also on the official social media censorship/suppression list?
Is the censorship status of Nord Stream pipeline something that can be checked? A quick google search suggests that such a status is plausible:
- Remarks at a UN Security Council Meeting on Leaks in the NordStream Pipeline, (US UN mission)
- Russians push baseless theory blaming US for burst pipeline, (AP News)
- Pro-China Disinformation Blamed US for Nord Stream Explosion, (Bloomberg)
- The claim by a discredited journalist that the US secretly blew up the Nord Stream pipeline is proving a gift to Putin, (Business Insider, India)
- U.S. podcasters spread Kremlin narratives on Nord Stream sabotage, (Brookings Institute)
- Biden also said the Russians have been “pumping out disinformation and lies”, (Radio Free Europe)
- Conspiracy Theorists, Right-wing Politicians Fuel Nord Stream Disinformation, (CEPA)
- Nord Stream pipeline disinformation fits pattern of Russian information warfare, (Cyberscoop)
- Nord Stream 1 & 2 Sabotage – Disinformation a la MH-17? (EU Disnfo)
Beyond Social Media Censorship: “Elite Gatekeeping”
There are a variety of ways of addressing this censorship issue, but rather that addressing the issue narrowly, I’d like to expand our conception of the problem beyond just the Twitter-style public-private “collaborative censorship” (my euphemism) to the general category of “elite gatekeeping,” which can include all manner of conventional and unconventional acts designed to manipulat information and attack opponents.
“Elite Gatekeeping” Example: Stacey Plaskett & Mehdi Hassan
I consider the work of delegate Stacey Plaskett and MSNBC journalist Mehdi Hassan to counter Matt Taibbi’s work on the Twitter File as a broader form of “elite gatekeeping,” which tried to protect the Democratic party from embarrassment and perhaps deter journalists from exposing abuse of of power.
Even if no backchannel continues to exist between the government and Twitter, elites will still likely gatekeep in an effort to counter people that undermine their power..
How Independent Media can Counter Elite Gatekeeping by Building Reader Trust
So given that the threat of elite gatekeeping (in the form of Plaskett – Hassan) will continue to exist even if the government is disentangled from social media moderation/censorship, how can independent media counter “Elite Gatekeeping?”
One way is by “showing up” the establishment media by demonstrating more trustworthy practices, such as superior citation transparency.
Take the following example of Matt Taibbi’s Nord Stream pipeline bombing article whose thesis is hard to deny.
- American officials have an extensive, years-long record of promising action to stop or disable the pipeline.
- Those earlier statements were ignored both by officials and press commentators in asserting ad nauseam that the West did not have motive for the attack.
- Three: despite a total absence of evidence, American voices repeatedly insisted Russia was behind the attack.
Overcoming Partisan Distrust
Could this article be presented in a way that is more persuasive and harder to attack as disinformation? I believe so, using CiteIt’s contextual citations.
Although a motivated reader could track down the original quote contexts, a skeptical rider is not likely to verify, and thus not trust the quotes, especially if they perceive the writer has a different partisan alignment.
- I found that a friend of mine who was unfamiliar with Matt Taibbi had framed Taibbi as a “right-winger” (and thus not to be trusted because my friend is left-wing and associated Taibbi with Elon Musk via the Twitter files).
Original Article: Unlinked Quotes
Below is what Matt Taibbi’s original article looked like originally, without the quotations being linked to their context.
If you think as a partisan skeptic, one might suspect that the quotes are taken out of context and remain unpersuaded.
Before: (screenshot)
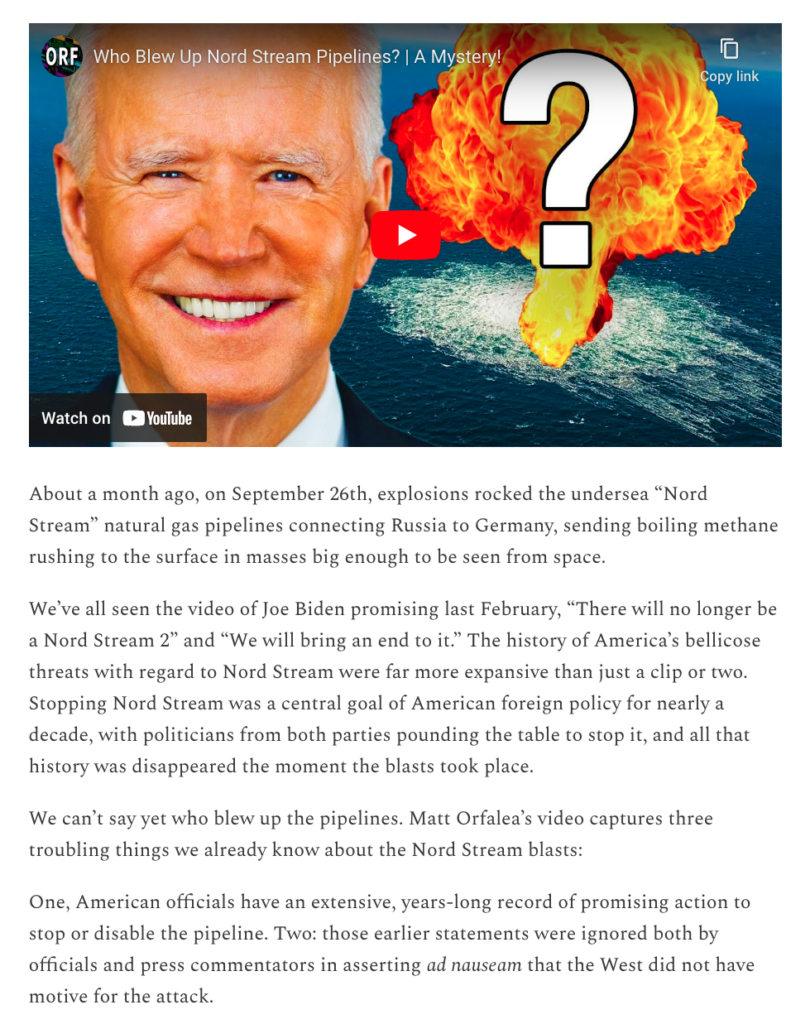
Original Article: We will bring an end to it
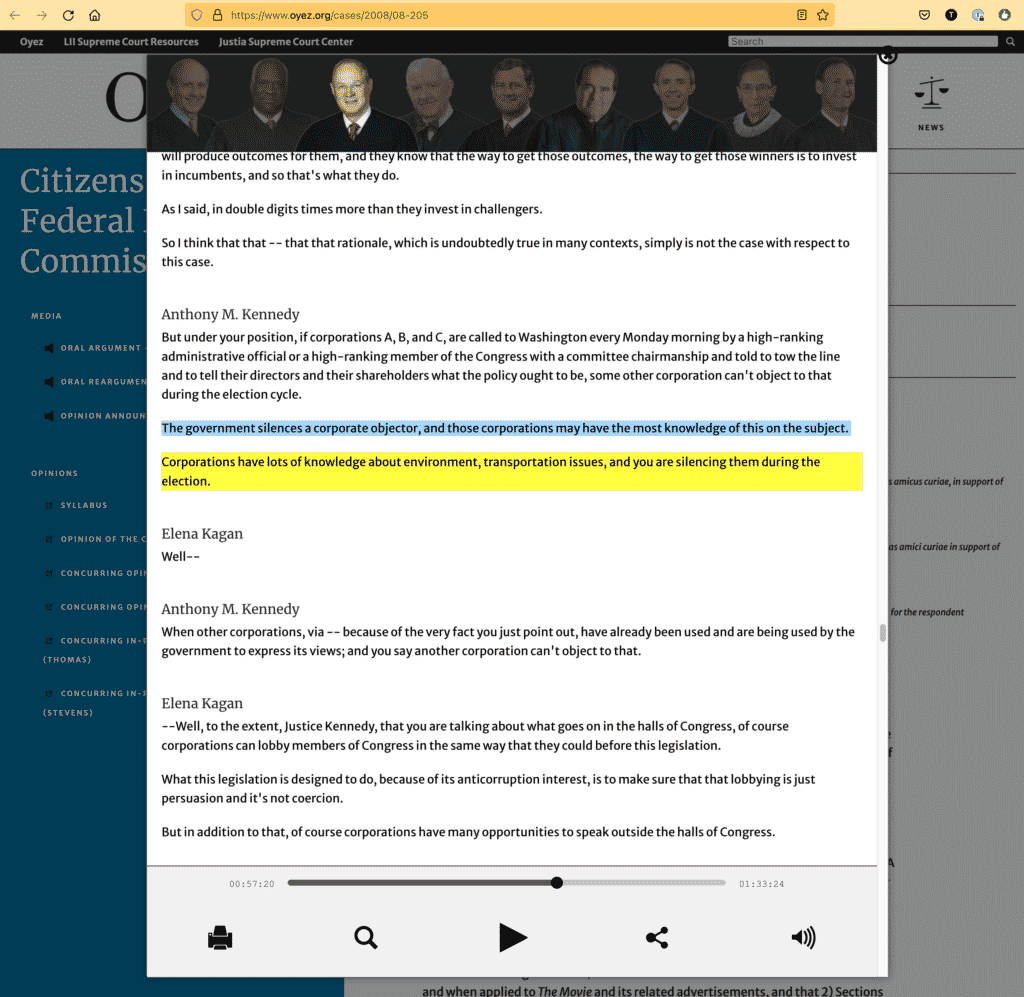
Showing Context: Linked Quotes
Compare the above example with what Matt Taibbi’s article looks like after quotes are linked to their sources.
This example simulates what the article would look like if the writer linked to YouTube videos, so that CiteIt can lookup and conveniently display a popup with the video and transcript context for the reader.
After: (screenshot)
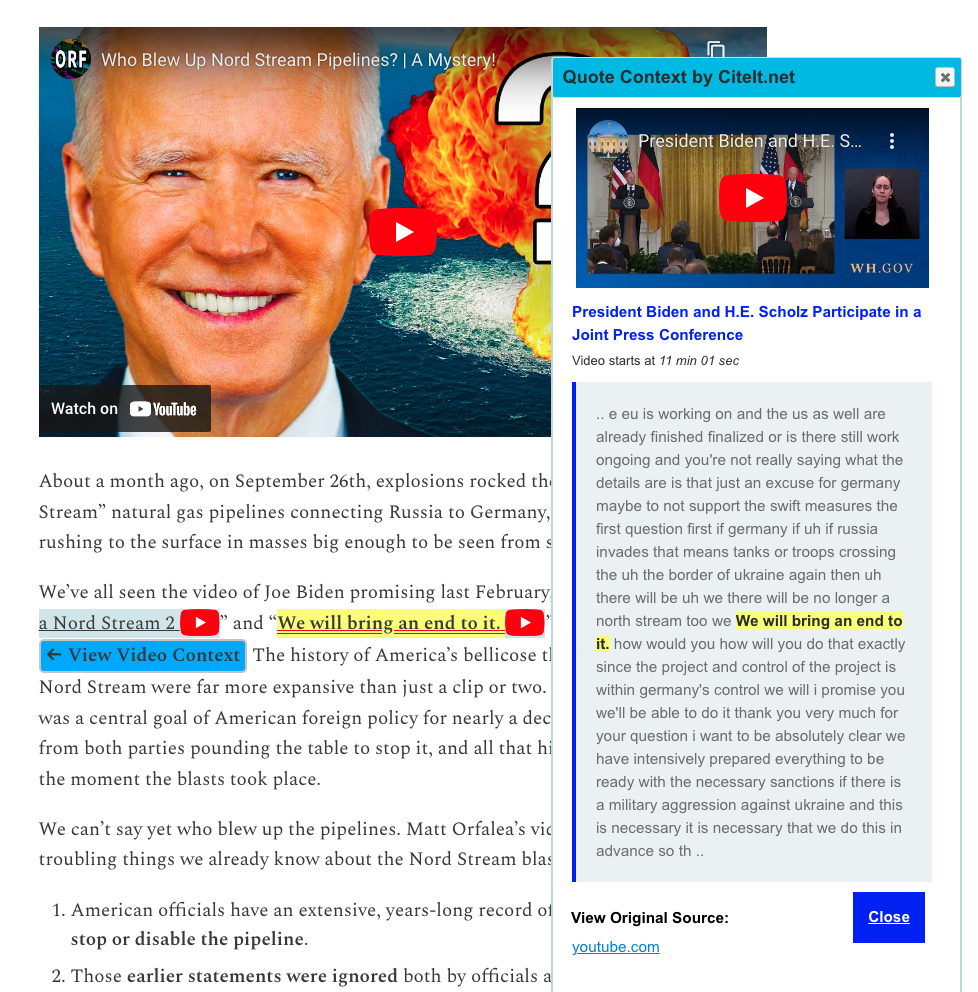
Contextual Popup: view linked video and transcript
How writers can create contextual quotations:
The goal of CiteIt is to help writers earn the trust of readers by making it as easy for writers to create contextual quotes as it is to create a normal link.
CiteIt automates the process of constructing a contextual popup from a web source or YouTube video URL.
View Demo Article:
- Who Blew Up the Nord Stream Pipelines? »
(with contextual Citation links)
Goals:
- Short term: Test CiteIt with Substack authors and get writer feedback.
- Long term: Partner with Substack to bring CiteIt’s contextual citations to a wide range of readers and writers.
Footnotes
The range of agencies requesting censorship was wide, even including the census agency.↩




{kind=link}